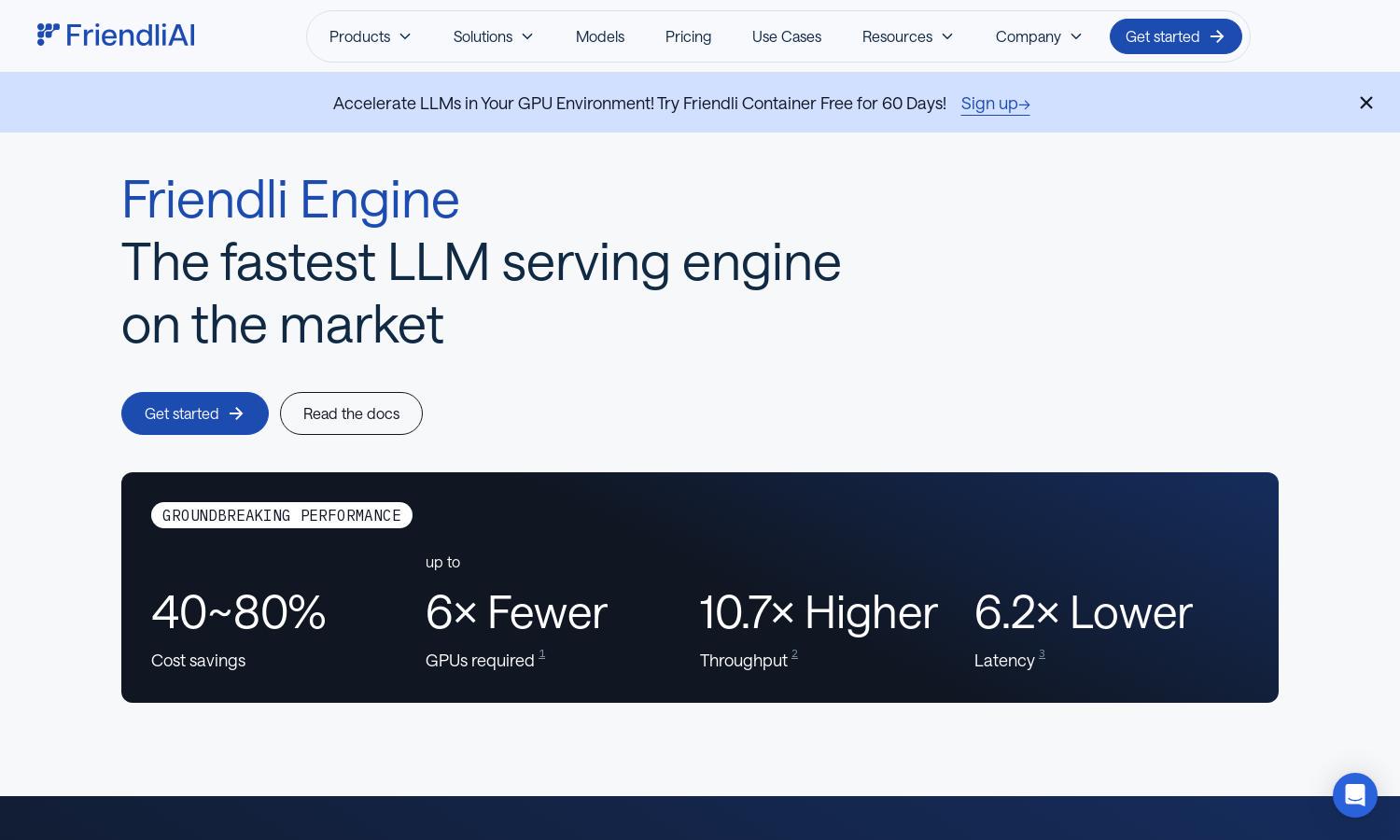
Friendli Engine
About Friendli Engine
Friendli Engine revolutionizes LLM inference, targeting businesses utilizing generative AI. It employs game-changing technology like iteration batching to optimize performance while reducing costs. Users benefit from faster deployment without compromising quality. With cutting-edge features, Friendli Engine is poised to support diverse AI applications efficiently.
Friendli Engine offers flexible pricing plans tailored to your needs. Users can choose from various subscription tiers, each providing distinct advantages like improved performance and dedicated support. Upgrading enhances access to advanced features and maximizes cost savings, making it a valuable investment for generative AI applications.
Friendli Engine features an intuitive user interface designed for seamless interactions. Its layout promotes easy navigation through complex features, making it accessible for users of all skill levels. Unique functionalities, such as efficient caching, enhance user experience, ensuring that each session is smooth and productive.
How Friendli Engine works
Users begin their Friendli Engine journey by signing up and onboarding with straightforward guided steps. After setting up their environment, they can easily navigate the platform to deploy and fine-tune generative AI models. The built-in tools simplify accessing advanced features, optimizing LLM inference, and enhancing real-time performance for users.
Key Features for Friendli Engine
Fast and Cost-Effective LLM Inference
Friendli Engine specializes in fast and cost-effective LLM inference, delivering unparalleled performance for generative AI. Users can achieve 50-90% cost savings and significantly reduced latency, enhancing their ability to manage and deploy sophisticated AI models efficiently, making it a standout solution in the industry.
Multi-LoRA Model Support
Friendli Engine enables seamless support for multiple LoRA models on a single GPU, streamlining LLM customization and efficiency for users. This pivotal feature allows for enhanced model versatility and accessibility, ensuring that deploying complex AI solutions remains achievable without excessive resource demands.
Speculative Decoding Feature
The speculative decoding feature in Friendli Engine accelerates LLM inference by intelligently forecasting future tokens while generating current outputs. This innovation provides users with faster response times and consistent results, making the engine exceptionally efficient for real-time applications in generative AI.








